In my role as a Data Scientist at the City of Cape Town, I’ve had the opportunity to work on a number of exploratory text-processing projects — from simple topic-modelling, to building custom text-classification models, to working with word-embeddings, audio-data, implementing semantic search and retrieval augmented generation, prompt evals, and more. Adding LLMs to my NLP tool-kit has been fun and frustrating, and I’ve learned a lot about the quirks and challenges of working with the technology. I’ve gained some hands-on experience in building products with both “open” LLM models (
llama,gemma,mistral,wizard, &c.) and commercial models (chatgpt,claude, &c.). A request the team gets a lot is to talk to people in other departments about “Generative AI” and LLMs, and to explain a bit about how they work. Here are some rough notes in that direction.
Some definitions
- The field of “Artificial Intelligence” (AI) develops technologies to emulate human performance in solving a variety of tasks
- “Machine Learning” (ML) is a sub-field of AI that develops statistical models that use relationships established in example data to make predictions with new data
- “Generative AI” is a type of ML that uses relationships established in example data to generate synthetic data that closely resembles the characteristics of the example data
What is a Large Language Model (LLM)
- Large Language Models are a type of Generative AI
- Think of LLMs as “synthetic” text generators
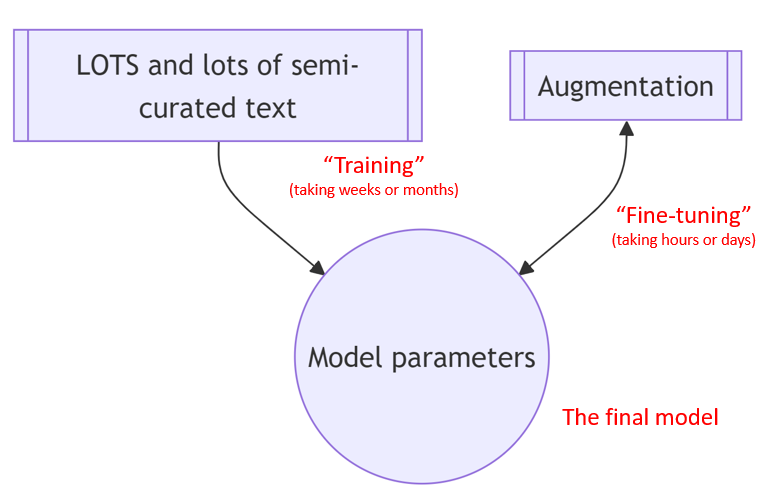
- An LLM model represents numerical relationships between billions of word fragments, combinations, and sequences, obtained from massive amounts of (semi-curated) text from the internet, books, news sources, forums, &c., and then augmented with additional feedback and examples to influence the way content is generated
- The better the quality and volume of data to draw relationships from, the better the ability of the model to create realistic and potentially useful content in response to — or “in continuation of” — new bits of text it is given, such as a question or a task from a user
- This is rather cool, because for quite a few things, these continuations will tend towards correctness (in the mundane sense). The flip-side is it can also tend towards the kind of common biases and misconceptions we see on the internet (despite efforts to avoid that), so watch out
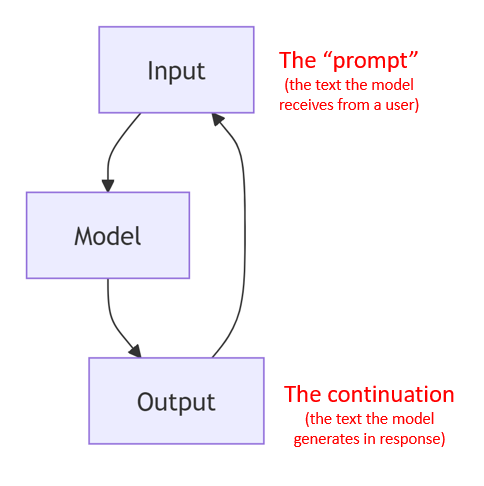
- You interact with an LLM model through a “prompt”. The “prompt” is whatever text you give the LLM and the history of the text you’ve given it and the text it generates, and so on
- bit of text (prompt) -> model -> continuation
- “What has this model likely seen a lot of?”, and “How can I get this LLM to generate something in the right vein”, are useful thoughts to have when interacting with these models
- The implication is that you can get better or worse answers depending on how you pose a question, i.e. what you put in the prompt and conversation history
Quick clarification
- Vanilla LLM: Trained on text, generates more text in continuation of the user’s prompt, for e.g. in answering a question — think OpenAI’s
ChatGPT-3.5, or Meta’sllama 3 - LLM “compound” model: Trained on text, has the ability to trigger other (external) processes like searching the web or a database to find bits of additional text to concatenate to the prompt. This can result in a more relevant or useful continuation in response to a user’s text — think Google’s
Geminior Microsoft’sCopilot. This is a form of “retrieval augmented generation” (RAG) where you enrich the prompt with potentially useful information the model was not trained on - Multi-modal model: Trained on a mix of things, including images or audio, not just text, depending — think OpenAI’s
GPT-4omodel and beyond - This post focuses on LLMs and how they work, but the general principle remains the same, i.e. they are synthetic content generators
Gotchas
- LLMs can be unreliable — they mimic human language, as encoded in their parameters, and are only “concerned” with generating a coherent sequence of words. A lot of the time that will tend towards the answer you’re looking for, but not always
- They are not a search-engine or a database of facts, they just generate text! But as mentioned before, there are approaches like RAG, in compound-models, where a prompt can be enriched by an external search process, i.e. “relevant” bits of additional text is concatenated to your prompt ahead of generation
- They are not “intelligent” in the sense of being intentional, or able to “reason” holistically, though efforts are being made to approximate “reasoning” better. And one can goad a kind of rudimentary reasoning pattern out of it with structured prompting techniques
- Nonetheless, they are immensely powerful, and can often be very useful if you know what you want to do
- Handle their output with skepticism, while having a clear idea in mind of what you want to achieve — i.e. “how do I direct this stream of words in a useful direction?”
Best use-cases
- Mundane, low-stakes tasks — boilerplate content, code, &c.
- Things you can check for correctness and monitor
- First passes, first drafts, &c.
- A complement to other Natural Language Processing (NLP) tasks — low-stakes ones you can check or improve over time, like text extraction, categorization, tagging, &c.
Conclusion
- You can’t outsource your good sense
- When trying to solve problems, break them down, think about what you are trying to achieve, the stakes, and the best tool for the job — sometimes an LLM is not the tool for the job!
- GenAI and LLMs can be extremely useful tools and time-savers, but are fundamentally unreliable, so consider how much that matters for the task you have in mind
- If you plan on doing something very ambitious, like automating some types of tasks with LLMs, I’d highly recommend you keep a human-in-the-loop, to check, approve, and monitor how the tool is doing
- Cultivate the idea of “LLM-as-tool” — a weird unwieldy tool — instead of “LLM-as-expert”
📎 Links
- GPTs
- Some prompting patterns
- Google’s NotebookLM
- The Financial Times’ piece Generative AI exists because of the transformer
- Transformer Explainer — “an interactive visualization tool designed for non-experts to learn about Transformers through the GPT-2 model” by Aeree Cho, Grace C. Kim, Alexander Karpekov and others
- [video] Andrej Karpathy’s LLMs for busy people
- Ted Chiang’s ChatGPT is a blurry JPEG of the web
- [paper] Michael Townsen Hicks, James Humphries & Joe Slater’s ChatGPT is bullshit
- Worth reading re copyright law: The New York Times’ case against Microsoft and OpenAI
- Jaron Lanier’s How to Picture A.I.
- [paper] Murray Shanahan’s Talking About Large Language Models — careful of anthropomorphizing LLMs, or assigning intent, it may affect how successful you are at using them
- [paper] Emily Bender, Timnit Gebru et al. On the Dangers of Stochastic Parrots
- Simon Willison’s Prompt injection and jailbreaking are not the same thing — Simon discusses some of the ways in which LLMs can be vulnerable
- Rohit Krishnan’s What can LLMs never do?
- An interesting read on the process of fine-tuning an LLM’s “character” by Anthropic: Considerations in constructing Claude’s character. I think Patrick House’s article is a great complement: The Lifelike Illusions of A.I
- Simon Willison’s Think of language models like ChatGPT as a calculator for words — a nice metaphor for LLMs, see also “the weird intern”
- Simon Willison’s Embeddings: What they are and why they matter
- Vicki Boykis’s list of “no-hype” reads on LLMs — great readings on the fundamentals of LLMs and more
- [book] AI Snake Oil: What Artificial Intelligence Can Do, What It Can’t, and How to Tell the Difference by Arvind Narayanan and Sayash Kapoor
- LLMs in production: Hamel’s “Your AI product needs evals” — relevant for when you are starting to think about the effect of your prompt tweaks on your outputs, and whether you are making things better or worse
- The What We Learned from a Year of Building with LLMs series by Eugene Yan, Bryan Bischof and others
- Against LLM maximalism by Matthew Honnibal (Explosion, spaCy) — “Instead of throwing away everything we’ve learned about software design and asking the LLM to do the whole thing all at once, we can break up our problem into pieces, and treat the LLM as just another module in the system…”